Editor’s note: This article initially featured a Matt Cutts misquote about Google’s ability to crawl Twitter, which has been updated as of August 16.
The most famous man in search delivered the opening keynote for SES San Francisco day two. Matt Cutts offered insights on Google’s shift toward the Knowledge Graph, social’s role in SEO and transparency for webmasters. He also fielded some tough questions from marketers on the rise of answers IN SERPs and how this could steal traffic from sites.
One of the key focuses for Google is moving away from being a search engine and toward becoming a knowledge engine. Cutts emphasized the Knowledge Graph has an increasingly important role in Google search (and some marketers were not pleased!) Check out Brafton’s coverage of the full Q&A session:
 Question 1 (from an SES San Francisco attendee): Is there a plan to improve the technology to focus less on content to understand a company’s quality in terms of products and services?
Question 1 (from an SES San Francisco attendee): Is there a plan to improve the technology to focus less on content to understand a company’s quality in terms of products and services?
Answer (from Matt Cutts):
Social will become an increasingly important way to get an understanding of what is the best quality. Links will always be part of that for Google, but Panda and Penguin will get more refined. Marketers and webmasters ask, “When’s the next Penguin update?” and maybe they shouldn’t seem excited. The Penguin updates will cause some SERP flux.
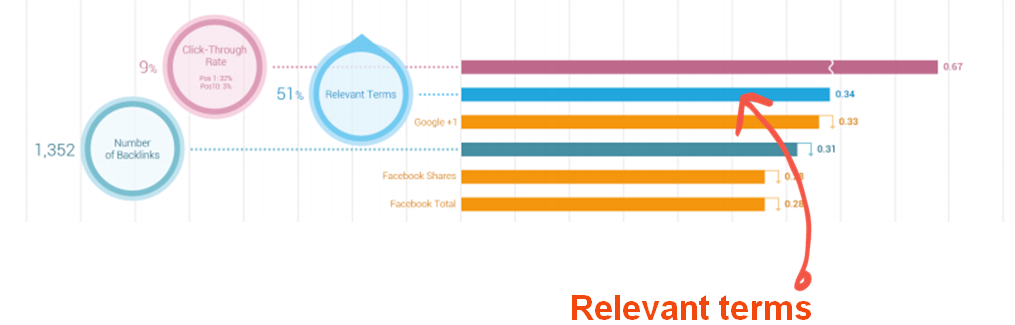
Q2: [Generally, the Q asked which social signals Google uses.]
Editor’s note: The initial release of this article misquoted Matt about Google’s ability to crawl Twitter. Matt Cutts has clarified that Twitter blocked Google from crawling for 1.5 months when the deal ended, and we’ve updated the article to reflect his answer.
A: Google can only use social signals from Open Graph sources. It can’t crawl Facebook pages to see who is reputable, reliable or has real world impact as a brand has on those platforms.
Q3: What happened with Twitter? [Google and Twitter ended their relationship in 2011]
People were upset when Realtime results went away! But that platform is a private service. If Twitter wants to suspend someone’s service they can. Google was able to crawl Twitter until its deal ended, and Google was blocked from crawling those pages for 1.5 months. As such, Google is cautious about using that as a signal – Twitter can shut it off at any time.
“Google is cautious about using [Twitter or other private social networks it is able to crawl] as a signal – Twitter can shut it off at any time.”
We’re always going to be looking for ways to identify who is valuable in the real world. We want to return quality results that have real world reputability and quality factors are key – Google indexes 20 billion pages per day.
Q4: What’s with the link messages people have been receiving?
Google is focusing on transparency. There was a Tweet about the link messages that said “it’s cheaper to go white hat in the long term” and that’s what Google is striving for. And by becoming more transparent Google can show it’s not giving special advantages to certain web properties. The link updates work toward that.
Notably, Google will not be not be giving specific info about its algorithms – that won’t become too transparent.
Q5: What about when you [Matt Cutts] said not to overly optimize?
A; If you’re doing good SEO, you’re focusing on content for users, you’re making your sites faster. My hold back on SEO referred to not buying backlinks. That Tweet about it being cheaper to go white hat is [essentially what Cutts aimed for when he said not to overly optimize]. SEO is good!
Q6: Is Google becoming less of a search engine and more of a publisher? Knowledge Graph provides information but is eating up traffic to other sites (especially Wikipedia) and Google Flights takes traffic away from Orbitz, etc. How many publishers are impacted? Should verticals be scared if they get on Google’s radar that Google will cannabolize traffic?
How many publishers are impacted [by Knowledge Graph and answers in SERPs]? Should verticals be scared if they get on Google’s radar that Google will cannabolize traffic?
A: Google is about answers. Wikipedia is focused on knowledge and probably approves. But for marketers that want to maximize traffic, the key will be to focus on content that has original value – such as original reviews, unique data or insights.
When a user types “What’s the weather?” there’s a straightforward answer Google can give. These are objective facts. When you want to get insights or reviews, such as “Where’s the best place to buy a car?” Google won’t be able to give a simple answer. Marketers have to focus on offering unique value for objective queries.
Q7: Where’s the line for what Google considers objective?
A: Users expect more every year. Users want to be able to find more information directly on the SEPRs. [Cutts had more to say on this. Typing fail!]
Q8: Google is doing right for itself, but how can others pay content writers? What about webmasters?
“For marketers that want to maximize traffic [in the face of Knowledge Graph and answers on SERPs], the key will be to focus on content that has original value – such as original reviews, unique data or insights.”
A: Google is focused on what’s good for the user. The search quality/ knowledge team doesn’t care about how much money Google makes – they focus on what’s good for users.
[The crowd is dissatisfied, Danny Sullivan offers a follow up question/comment.]
Q9: [from Sullivan] For sites that are built on sharing facts, Google IS taking their business. It may be good for the user, but if Google is extracting the content to do what’s good for users … At the same time, Google still delvers the majority of traffic to sites.
A: Google’s focus is on the best user experience, but we are mindful of webmasters. Users HAVE to come first or searchers will go elswhere, but we understand the web IS websites, and it needs to be good for webmasters. Otherwise people would move to apps and search wouldn’t work out.
In Google’s “10 things we know to be true,” we profess our dedication to focusing on the users.
Q10: Is it possible Google would release statistics about percentage of clicks to going to organic results over Google products or paid results, as well as if its top 5,000 domains or little guys?
A: I can make no promises, even if that would be great. A way to do that is to accumulate the rankings and see what Sistrix calls the sites that move up or down as an imperfect indicator. I’ll pass that suggestion on because we are moving to transparency. [He suggests it will be difficult because of the sheer volume of queries Google handles.] We field 3 billion searches each month.
“Users HAVE to come first or searchers will ditch Google, but we understand the web IS websites, and it needs to be good for webmasters.”
Q11: [The question centered on how rankings have changed since Panda.]
A: There’s a site that measures how many times Google ranks original content as top results, and with Panda they are striving to achieve this.
Q12: Can you talk about the importance of Google+ since Google wants to be more social but doesn’t have access to other platforms?
A: We haven’t put a LOT of weight on +1s yet. Google wants to consider social data, but +1s aren’t everything – Google considers feedback about Search Plus Your World.
Q13: Do Google products (ie: YouTube) give higher rankings? Should marketers publish on Google properties?
A: We want people to be able to trust Google [not favor Google in results unmerited].

Q14: From a content writer’s perspective, what are the key technologies in Knowledge Graph and how can we make it an SEO tecnique?
A: The primary part of what we’re building Knowledge Graph off of is Freebase. It remains open source. You can download the data from Freebase and use it yourself. If you see something inaccurate, you can report it. Google doesn’t fix that, but Wikipedia, for example, will. If you want to know the data Google has under the hood – on people, versus locations, etc. – you can check it out there.
Q15: Why doesn’t Google have a rating system? If you’re moving to transparency, why isn’t there a tool that shows what you’re doing wrong so a site can do better in its space?
A: Giving actionable data on how to make a site better is exactly the direction that Google wants to be moving in. If there’s spam, we want to say, “Yes, we found spam.” This speaks to the unnatural links warnings. Now we’ve started saying: we think the site is good, but we don’t trust some of these links. Hopefully marketers can see what went wrong so they can change it. That’s the vision.
Of course, sometimes the message gets confused [people panicked with the new link messages!] so the delivery needs to be good.
“Giving actionable data on how to make a site better is exactly the direction that Google wants to be moving in.”
It’s useless if we tell webmasters, “We don’t trust you,” but we don’t give insights. By the end of the year, we hope to offer more on that.
Q16: The SEO community is in panic since Panda and Penguin, and people are rewriting all types of content. Can you speak to this?
A: Panda went after low-quality content. It was a big change, but it’s what we felt was best for users. Last year, everybody was asking about Panda, and now the market seems to have shifted. People understand good content, research, unique content with value is essential to SEO.
It was then that we were able to look at linking, so Penguin came out. People were shaken by that, and sites that have social sharing, natural sharing – instead of buying links – are generally not going to be hit. By next year, we hope marketers/ webmasters get that and natural link building becomes the norm.
[To the Panda query about “rewriting all types of content] If it’s the same content on different pages of your site, repeating your own content yourself, you might not be impacted but don’t use the same boilerplate content on every single page.
[Stay tuned for more SES San Francisco updates.]